Project: Crypto Medallion ETL (Bronze → Silver → Gold)
Overview
A multi-layer (Bronze → Silver → Gold) ETL pipeline that ingests live cryptocurrency market data from the CoinGecko API, stores raw and cleaned records in PostgreSQL, and produces daily aggregated insights. The pipeline is orchestrated by pipeline.py, version-controlled on GitHub, and implemented in Python (Anaconda). The Claude AI agent assisted during development. Logs are written to etl.log.
Goals
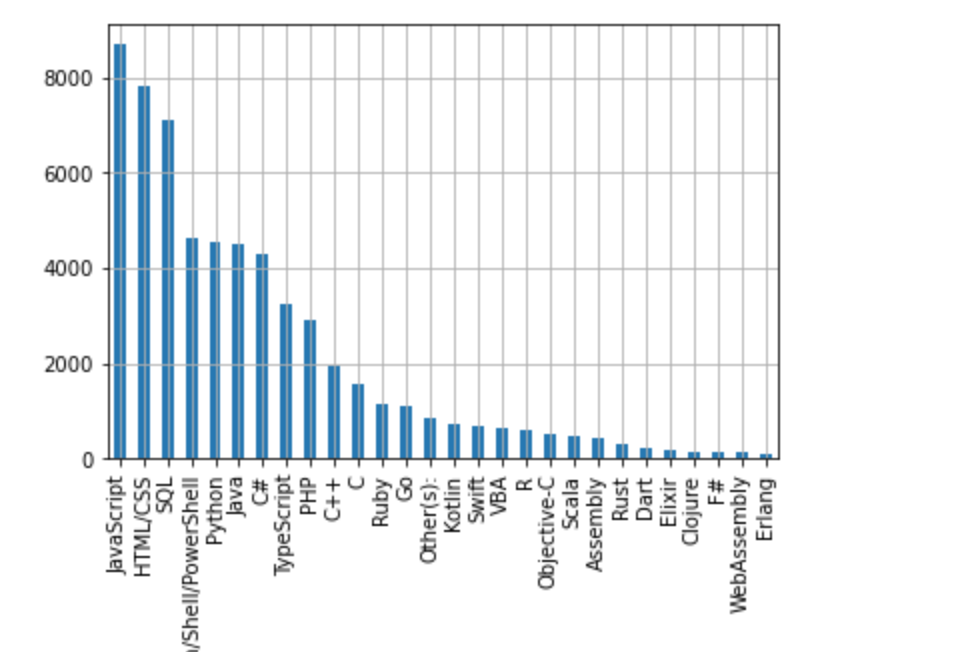
Ingest top N coins from CoinGecko on an hourly cadence.
Preserve raw extracted records (Bronze) for auditing and reprocessing.
Enrich and normalize data (Silver) for analysis-ready consumption.
Produce daily aggregated summaries and top-movers (Gold) for reporting and downstream analytics.
Architecture — Medallion Layers
CoinGecko API
▼
Bronze Layer → coins table
▼
Silver Layer → coins_silver table
▼
Gold Layer → gold_daily_summary + gold_top_movers
Bronze: extract.py → transform.py → load.py → coins table
Silver: silver.py → coins_silver table
Gold: gold.py → gold_daily_summary + gold_top_movers tables
Orchestration: pipeline.py. runs all three layers end-to-end
Automation cron job runs pipeline.py every hour (add manually via crontab -e)
Data Flow (High-level)
- pipeline.py triggers extraction, transformation, loading for Bronze.
- Bronze layer persists cleaned raw snapshots to
coins. - Silver layer reads recent Bronze snapshots, enriches data (derived fields, currency normalization), and writes to
coins_silver. - Gold layer computes daily summaries and top movers and writes to
gold_daily_summaryandgold_top_movers. - Cron schedules pipeline hourly.
Project Structure
├── pipeline.py # Orchestrates full Bronze → Silver run → Gold
├── extract.py # Fetch top N coins from CoinGecko API
├── transform.py # Select and clean fields (Bronze)
├── load.py # Insert into Bronze coins table
├── silver.py # Extract from Bronze, enrich, load into Silver
├── config.py # DB connection via .env credentials
├── db_setup.sql # SQL to create coins and coins_silver tables
├── etl.log # Auto-generated pipeline log
├── #test_extract.py # Unit test for extract
├── # test_transform.py # Unit test for transform
├── #test_load.py # End-to-end Bronze pipeline test
└── test_silver.py # End-to-end Silver pipeline test
Environment
– Python 3.8 (Anaconda) — ~/opt/anaconda3/bin/python
– PostgreSQL with psycopg2
– Credentials stored in .env (not committed to git)
– Logs written to etl.log